Зачем remote_write и почему именно VictoriaMetrics
Prometheus отлично справляется со сбором метрик и коротким горизонтом хранения, но с ростом инфраструктуры возрастают кардинальность, нагрузка на диск/ОЗУ и требования к истории. Типовой путь — вынести долгосрочное хранение и тяжёлую аналитику в отдельную TSDB, оставив Prometheus быстрым скрейпером и алертером.
Связка prometheus + remote_write + victoriametrics решает задачу: VictoriaMetrics экономно хранит месяцы истории и масштабируется независимо от сборщиков.
- Надёжная доставка: очереди, ретраи, устойчивость к кратковременным сбоям.
- Масштабирование приёмника независимо от Prometheus.
- Гибкий ретеншн: от общего срока до изоляции по классам метрик.
- Снижение нагрузки на Prometheus: долгую историю и тяжёлые запросы отдаём в VM.
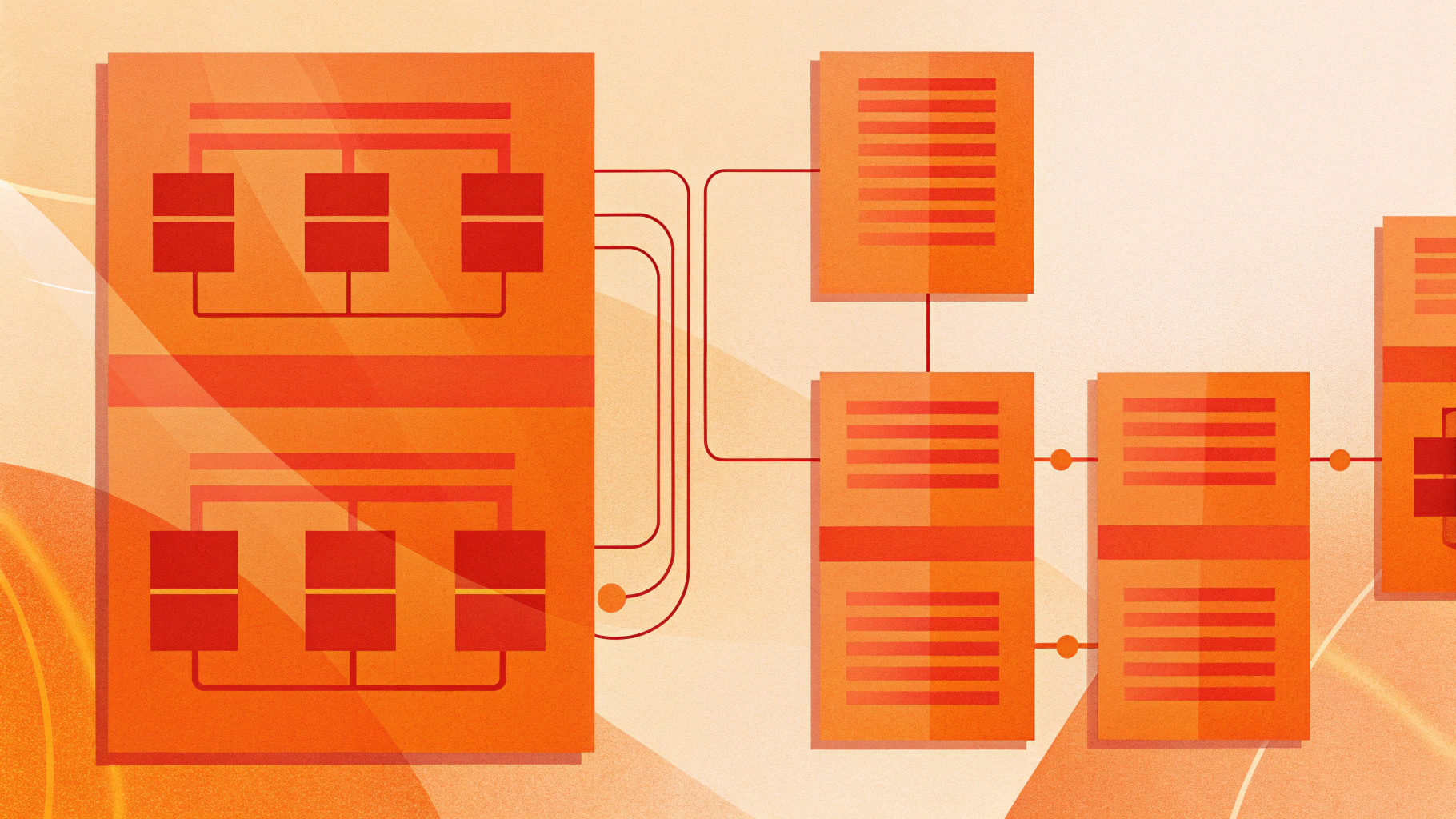
Архитектуры: от простого к отказоустойчивому
Вариант A: Прямой remote_write в single-node VictoriaMetrics
Самый простой старт — один экземпляр VictoriaMetrics (single-node), принимающий /api/v1/write. Плюсы — минимум компонентов и простота. Минусы — единая точка отказа и ограниченная масштабируемость.
Вариант B: Кластерная VictoriaMetrics
Для высоких нагрузок — кластер: vminsert принимает запись, vmstorage хранит, vmselect отвечает на чтение. Prometheus пишет в vminsert. Легче масштабировать и обслуживать без даунтайма, но сложнее в развёртывании и мониторинге.
Вариант C: Прокладка через vmagent с дисковым буфером
vmagent принимает remote_write от Prometheus и ретраит доставку с дисковым буфером. Это снижает риск потерь при перезапусках и длинных сетевых разрывах приёмника.
Вариант D: HA Prometheus и дедупликация
Два Prometheus со схожими конфигами пишут в один приёмник. На чтении используйте dedup() для скрытия дублей. Получаем устойчивый сбор и доставку без потерь при падении одного скрейпера.

Начинайте с простого single-node, добавляйте vmagent при первых признаках потерь, а при росте нагрузки переходите на кластер.
Если вы поднимаете хранилище и скрейперы в облаке, удобнее стартовать на управляемом VDS, чтобы быстро масштабировать CPU/диски и разделять роли по инстансам.
Настройка Prometheus: практичные пресеты remote_write
Блок remote_write в prometheus.yml задаёт адрес получателя и параметры очереди. Базовый шаблон с безопасными значениями для старта:
remote_write:
- url: http://vm:8428/api/v1/write
name: vm
remote_timeout: 30s
send_exemplars: true
send_native_histograms: true
write_relabel_configs:
- action: labeldrop
regex: __meta_.+
queue_config:
capacity: 20000
min_shards: 4
max_shards: 16
max_samples_per_send: 5000
batch_send_deadline: 5s
min_backoff: 1s
max_backoff: 60s
retry_on_http_429: true
Ключевые настройки:
capacity— общий размер очереди семплов для сглаживания всплесков.min_shardsиmax_shards— параллелизм отправки; повышайте постепенно, смотря на метрики.max_samples_per_sendиbatch_send_deadline— баланс нагрузки на сеть/CPU и задержек.retry_on_http_429— корректная реакция на бэкпрешер приёмника.write_relabel_configs— фильтруйте шум/временные метки ещё до отправки.
Очереди, бэкпрешер и контроль скорости
Смотрите на prometheus_remote_storage_samples_pending, prometheus_remote_storage_shards и коды ответов. Если растёт очередь или часто видите 429, снижайте давление: уменьшайте батчи, шардов или усиливайте приёмник.
Exemplars и native histograms
Современные Prometheus и клиенты поддерживают exemplars и «родные» гистограммы. VictoriaMetrics их принимает. Проверьте версии и оцените рост объёма — для метрик RPS и latency выгода в разборе инцидентов обычно окупается.
Приём и хранение в VictoriaMetrics
Single-node VictoriaMetrics с ретеншном в месяцах:
victoria-metrics -storageDataPath=/var/lib/victoria-metrics -retentionPeriod=12 -httpListenAddr=:8428-retentionPeriod определяет срок хранения. Для KPI часто хватает 3–6 месяцев, для трендов и сезонности — 12–18.
В кластере роли разделены: vminsert принимает запись, vmstorage хранит и применяет ретеншн, vmselect отвечает на чтение. Масштабирование независимое: добавляйте vminsert под запись и горизонтально расширяйте vmstorage под историю.
Политики ретеншна: глобально, изолированно, безопасно
Базовый вариант — единый глобальный ретеншн (флаг запуска). Для разных профилей данных удобнее логическая изоляция: отдельные инстансы с различными сроками хранения и маршрутизацией наборов метрик через правила relabeling.
Точечные удаления серий по селекторам и интервалам помогают прибрать шумные метки, попавшие в продакшен, без изменения глобального ретеншна.
Надёжность доставки: где теряются метрики и как этого избежать
- Добавьте vmagent с дисковым буфером между Prometheus и VictoriaMetrics.
- Используйте HA-двойки Prometheus и
dedup()на чтении. - Держите умеренные значения
capacityиmax_shards— избегайте как дропов, так и лавинообразной нагрузки. - Ограничивайте кардинальность до отправки через
write_relabel_configsи настройки экспортеров.
Наблюдаемость канала: что смотреть и на что алертить
Минимальные метрики Prometheus по каналу:
prometheus_remote_storage_samples_pending— размер очереди; не должен расти бесконечно.prometheus_remote_storage_samples_totalиprometheus_remote_storage_samples_failed_total— доля ошибок.prometheus_remote_storage_shardsиprometheus_remote_storage_shards_desired— саморегулирование параллелизма.prometheus_remote_write_requests_totalпо статусам — всплески 4xx/5xx сигнализируют о лимитах или сбоях.
Пример простых алёртов:
groups:
- name: remote_write
rules:
- alert: RemoteWriteQueueGrowing
expr: prometheus_remote_storage_samples_pending > 100000
for: 10m
labels:
severity: warning
annotations:
summary: Prometheus remote_write очередь растёт слишком долго
- alert: RemoteWriteHighErrorRate
expr: rate(prometheus_remote_storage_samples_failed_total[5m])
/
rate(prometheus_remote_storage_samples_total[5m])
> 0.05
for: 5m
labels:
severity: critical
annotations:
summary: Ошибка отправки семплов remote_write превышает 5%
Для end-to-end проверки доступности эндпоинта приёмника удобно добавить черный ящик; пример готового подхода см. в статье про blackbox-пробы HTTP/TCP/ICMP: как мониторить внешние проверки.
Практические рецепты оптимизации
Стабильные батчи
Для нестабильной сети начните с max_samples_per_send 2000–5000 и batch_send_deadline около 5s. Дальше увеличивайте, опираясь на p95/p99 латентности записи.
Кардинальность под контролем
Главный враг TSDB — «взрыв» кардинальности. Запрещайте бесконечные ID в лейблах (например, сырой URL в path, uid, trace_id). Режьте на краю через write_relabel_configs, в хранилище периодически удаляйте шумные серии.
HA-доставка с дедупликацией
Две реплики Prometheus, пишущие одни и те же метрики в VictoriaMetrics, повышают надёжность. На чтении используйте дедупликацию:
sum(dedup(rate(http_requests_total{job="api"}[5m])))Согласуйте external_labels и имена реплик, чтобы дедупликация и группировки работали предсказуемо.
Изоляция потоков по важности
Разделяйте «критичные продакшен», «операционные» и «стендовые» метрики по разным приёмникам или срокам хранения. Так один шумный источник не обрушит доступность всего контура.
Отладка и типичные ошибки
- 4xx при записи. Часто некорректные метки или лимиты приёмника. Проверьте длины, число лейблов и формат. Включите relabeling до отправки.
- 429 Too Many Requests. Признак бэкпрешера. Уменьшайте батчи/шарды или увеличивайте ресурсы и параллелизм на приёмнике.
- Потери после рестартов. Вставьте vmagent с дисковым буфером или сокращайте окна рестартов.
- Ступенчатый рост диска. Признак взрыва кардинальности или «высокочастотных» рядов. Найдите источник и включите фильтрацию.
Безопасность и доступ
Трафик remote_write может содержать чувствительные метрики. Минимальные меры:
- TLS-шифрование канала между отправителем и приёмником. Собственные SSL-сертификаты упростят управление и аудит.
- Аутентификация на приёмнике или на обратном прокси перед ним.
- Сегментация сети и доступ только с доверенных адресов.
- Раздельные учётные данные и ротация ключей для разных инстансов.
Не забудьте мониторить сроки действия сертификатов и заранее алертить об их истечении: пригодится пошаговая инструкция по алёртам на SSL: как следить за окончанием SSL.
Чек-лист перед запуском в продакшен
- Определена архитектура: прямой write, через vmagent или кластер.
- Настроены очереди
remote_write, проверены задержки и ретраи. - Определены политики ретеншна и при необходимости изоляция по классам данных.
- Добавлены алёрты на очередь, процент ошибок и рост диска.
- Ограничена кардинальность: relabeling и процесс ревью метрик.
- Закрыт периметр: TLS, аутентификация и сетевые ACL.
Итоги
Связка prometheus + remote_write + victoriametrics даёт устойчивую и предсказуемую доставку метрик в долгосрочное хранилище. Выберите подходящую архитектуру, начните с умеренных пресетов, включите наблюдаемость и держите кардинальность под контролем — получатся надёжные «трубы» метрик, переживающие пики и регламентные работы.


