
Зачем нужен VPA, если уже есть HPA
В Kubernetes легко перепутать два разных «автоскейлинга». Horizontal Pod Autoscaler (HPA) отвечает на вопрос «сколько подов нужно», а Vertical Pod Autoscaler (VPA) — «какой размер пода правильный».
Проблемы обычно начинаются с базового: resources.requests ставят «на глаз», а затем удивляются, почему HPA не масштабирует или делает это странно. Особенно когда HPA настроен на CPU utilization: эта метрика считается относительно requests.
- Завышенные requests → utilization низкий → HPA «не видит» нагрузку.
- Заниженные requests → utilization высокий → HPA может дёргать реплики, а поды успевают упереться в OOM/CPU throttling раньше, чем придёт масштабирование.
VPA — не «ускоритель», а «калибровщик» requests/limits: делает планирование предсказуемым, а метрики для HPA — осмысленными.
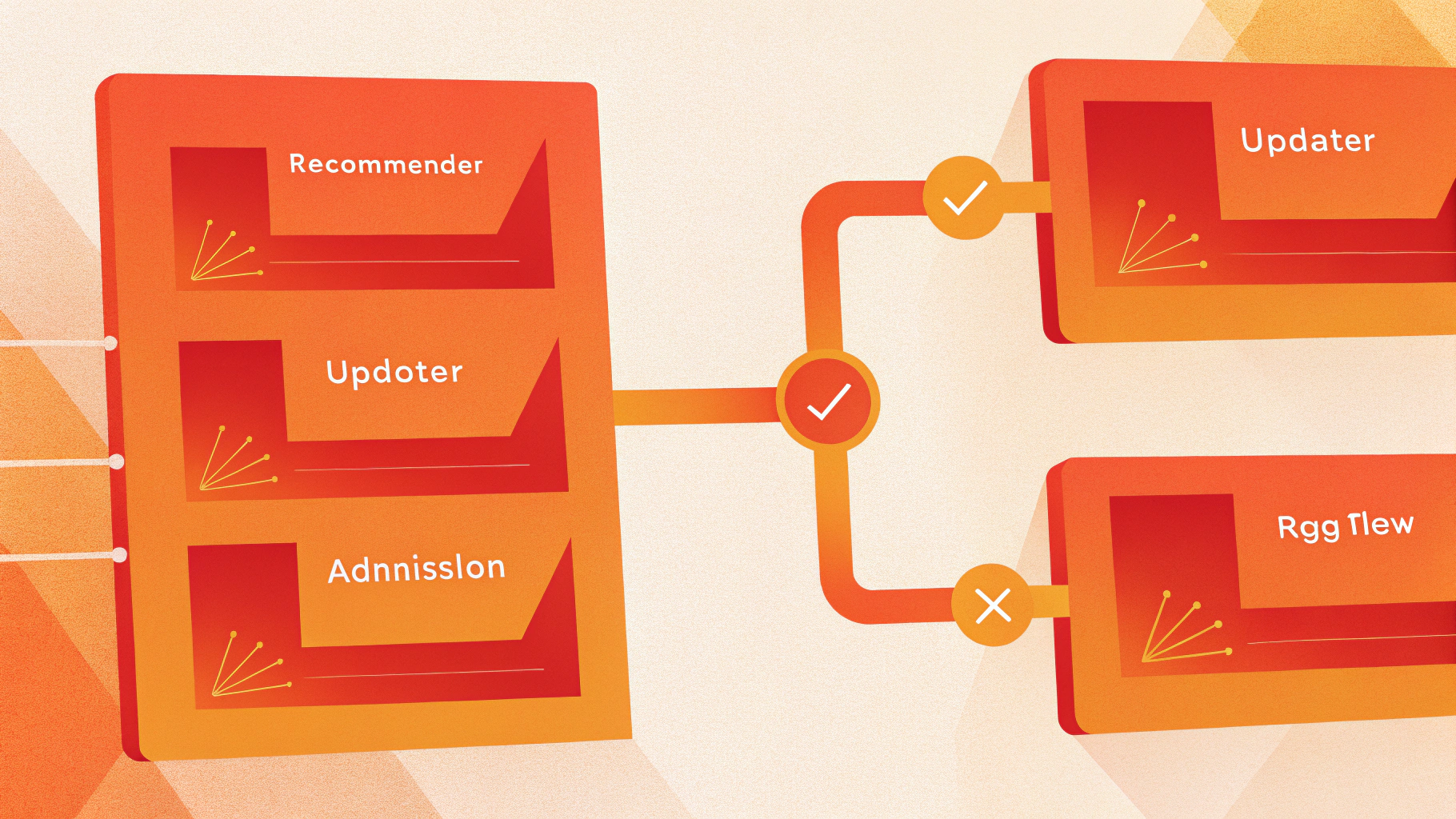
Как устроен Vertical Pod Autoscaler: Recommender, Updater, Admission Controller
Типовая установка VPA состоит из трёх компонентов, у каждого своя задача:
- Recommender — анализирует исторические метрики потребления и считает рекомендации по
resources.requests(CPU/память) для контейнеров. - Updater — сравнивает текущие requests запущенных подов с рекомендациями и решает, пора ли применять изменения. Применение чаще всего означает evictions (выселение/перезапуск подов).
- Admission Controller — mutating webhook: подставляет рекомендованные requests в момент создания пода, чтобы новые реплики сразу стартовали с корректными ресурсами.
Ключевая идея: Recommender только «советует», а фактическое применение происходит через Admission Controller (для новых подов) и через Updater (для уже работающих подов — через evictions).
Что именно считает Recommender и почему рекомендации «плавают»
ВPA обычно формирует несколько оценок: нижнюю границу, целевое значение и верхнюю границу. Дальше вы задаёте политику: например, не опускать requests ниже минимума и не поднимать выше максимума, чтобы избежать «нервных» изменений из-за разовых всплесков.
На практике для оценки качества рекомендаций важны два вопроса:
- Как быстро VPA реагирует на изменение профиля нагрузки (пики/спады)?
- Будет ли он провоцировать перезапуски и «дрожание» requests при включённом автоприменении?
Если у сервиса резкие всплески и длинные «холодные» плато, VPA может активно занижать requests, а следующий пик даст деградацию. Поэтому безопасный путь — начинать с рекомендаций и ручной валидации.
Updater и evictions: почему VPA может «ронять» поды
Requests у уже запущенного пода «на лету» не меняются. Поэтому Updater применяет рекомендации, инициируя evictions: под удаляется, а контроллер (Deployment/StatefulSet) создаёт новый — и уже он проходит через Admission Controller с обновлёнными requests.
Отсюда практические следствия, которые лучше подготовить заранее:
- Нужны корректные
readinessProbeи достаточный запас по репликам, иначе оптимизация превращается в простой. - Для stateful-нагрузок надо отдельно продумать порядок перезапусков и влияние на кворум/репликацию.
- Нужны PodDisruptionBudget и согласование с rollout-стратегиями, иначе VPA может сложиться по времени с drain ноды/обновлением и дать неприятный суммарный эффект.
Admission Controller: где чаще всего ломается внедрение
Admission Controller зависит от webhook-инфраструктуры. Типовые причины проблем:
- Жёсткие NetworkPolicy: API server не может достучаться до сервиса webhook.
- Проблемы с сертификатами webhook или CA bundle.
- Режим «fail closed»: при любой ошибке webhook создание подов блокируется.
Перед автоматическим применением полезно проверить деградационный сценарий: что будет, если webhook станет недоступен на 5–10 минут. Для практики по защите webhooks от злоупотреблений и повторов запросов может пригодиться разбор про защиту webhook через HMAC и анти-replay.
Режимы работы VPA: Off, Initial, Auto — что выбрать
В большинстве реализаций VPA встречаются три режима (формулировки могут отличаться, смысл одинаковый):
- Off — VPA только считает рекомендации, ничего не применяет.
- Initial — рекомендации применяются только при создании пода (через Admission Controller). Уже запущенные поды не трогаются, то есть Updater не инициирует evictions.
- Auto — рекомендации применяются и к новым, и к существующим подам, используя Updater и evictions.
Практический маршрут внедрения обычно такой: Off на 1–2 недели (или хотя бы на полный цикл типичной нагрузки), затем Initial. В Auto имеет смысл идти только когда вы уверены в probes, PDB и готовности сервиса к плановым перезапускам.
Что реально меняется: requests, QoS и влияние на планирование
VPA в первую очередь влияет на resources.requests. Именно requests определяют:
- как scheduler размещает поды по нодам (capacity planning);
- какой QoS-класс получит под (а значит — поведение при давлении на ресурсы);
- как считается CPU utilization для HPA, если HPA настроен на utilization.
Частая ошибка — ждать, что VPA «поднимет limits и исчезнут OOM». OOM чаще связан с тем, что limits.memory слишком низкий или у приложения утечки/неуправляемый рост памяти. VPA может рекомендовать поднять requests, но limits — это отдельная политика.
Если вам нужен предсказуемый продакшен, держите в голове простое правило: requests — это то, что кластер обещает поду, а limits — то, что поду разрешено потратить. Для burst-режимов разумно держать limits выше requests, но не ставить их «впритык» к ресурсам ноды, иначе возрастает риск массовых вытеснений и деградаций соседей.
HPA и VPA вместе: рабочие схемы и конфликтные зоны
Запрос «hpa vpa together» встречается часто не просто так: неправильная комбинация приводит к «качелям» по репликам и ресурсам.
Где возникает конфликт
Классический конфликт: HPA масштабирует по CPU utilization, который зависит от requests, а VPA меняет requests. Если VPA уменьшит requests, utilization вырастет — и HPA начнёт добавлять реплики. Если VPA увеличит requests — utilization упадёт, и HPA начнёт убирать реплики. Это не баг, это логика метрики.
Схема 1: VPA как рекомендатель, HPA как исполнитель
Самая безопасная схема для продакшена:
- VPA работает в Off или Initial, вы используете его как источник рекомендаций по
resources.requests. - HPA продолжает управлять количеством реплик.
Плюс: вы избегаете evictions от Updater, а requests меняются только при пересоздании подов в рамках обычных релизов.
Схема 2: HPA по метрикам, не зависящим от requests
Если HPA масштабирует не по utilization, а по метрикам уровня нагрузки (RPS на pod, latency, длина очереди), влияние VPA на решения HPA резко снижается. Это один из наиболее устойчивых вариантов для нагруженных систем.
В этом случае VPA «лечит» планирование и QoS через requests, а HPA управляет количеством реплик по метрике, которая отражает реальную нагрузку или backpressure.
Схема 3: VPA Auto только для отдельных ворклоадов
Auto имеет смысл включать точечно: например, для batch-воркеров или сервисов, где перезапуск пода безопасен и не приводит к потерям. Для API, где важна стабильность и предсказуемость, чаще оставляют Initial или Off.
Практика: с чего начать внедрение VPA в реальном кластере
1) Проверьте базовую «гигиену» ресурсов
Перед тем как доверять рекомендациям, проверьте, что метрики не искажены:
- CPU throttling из-за слишком низких
limits.cpu(в таком случае потребление «срезано», и VPA недооценивает CPU); - скачки памяти из-за кешей/GC: иногда правильнее настраивать приложение, а не только requests;
- разные профили нагрузки контейнеров в одном поде (sidecar может «съесть» память, и рекомендация окажется неожиданной).
2) Начните с рекомендаций и задайте рамки (policy)
Даже в режиме Off полезно задать ограничения: минимальные и максимальные значения CPU/памяти. Это защита от ситуаций, когда один случайный пик или аномальная метрика приводит к рекомендациям, которые потом долго мешают эффективному размещению.
3) Планируйте evictions как плановые disruption
Если вы идёте в Auto, относитесь к evictions как к регулярным плановым перезапускам:
- настройте PodDisruptionBudget и проверьте, что минимальное число реплик остаётся доступным;
- согласуйте стратегию rollout у Deployment со степенью агрессивности VPA, чтобы не получить слишком много недоступных подов одновременно;
- проверьте сценарии деградации зависимостей (БД/кеш/очереди): одновременные перезапуски могут синхронно поднять нагрузку на зависимости.
Диагностика и типовые проблемы
VPA «советует странное»: слишком мало CPU или памяти
Частая причина — метрики отражают не реальную потребность, а ограничения. Пример: низкие CPU limits приводят к постоянному throttling, фактическое потребление выглядит маленьким, и VPA занижает рекомендации.
По памяти бывает наоборот: приложение периодически раздувает кеш и держит его долго, VPA начинает рекомендовать высокий requests.memory, хотя по сути это «управляемый аппетит», который лучше ограничить настройками приложения.
Admission Controller мешает создавать поды
Если webhook недоступен или неправильно настроен, новые поды могут не создаваться (в зависимости от failurePolicy). На этапе внедрения выбирайте стратегию отказа так, чтобы кластер не останавливался из-за проблем VPA, и обязательно мониторьте ошибки и задержки webhook.
HPA начал «качать» реплики после включения VPA
Проверьте, не настроен ли HPA на CPU utilization и не меняет ли VPA requests в сторону уменьшения. В таких сценариях обычно делают одно из трёх:
- фиксируют requests вручную по рекомендации VPA (Off/Initial);
- переводят HPA на метрику, независимую от requests;
- оставляют VPA в Initial/Off и не включают Auto для этого ворклоада.
Короткий чеклист перед продакшеном
- Есть разумные стартовые
resources.requests, чтобы избежать хаотичного размещения. - Настроены
readinessProbe/livenessProbe, сервис выдерживает перезапуски. - Есть PodDisruptionBudget и понятная стратегия rollout.
- Понимаете, как HPA считает метрику и как изменения requests повлияют на scaling.
- Продумана деградация webhook (Admission Controller): что будет при его недоступности.
Вывод
Kubernetes VPA полезен там, где requests ставятся «примерно», и из-за этого страдают планирование и масштабирование. Он даёт поддерживаемую временем базу для ресурсов: либо как рекомендатель, либо как автоматический корректировщик.
Главные риски — evictions и взаимодействие с HPA через метрики, зависящие от requests. Если нужен быстрый эффект без сюрпризов: включайте VPA в режиме рекомендаций, фиксируйте requests по его данным, и только затем решайте, где уместны Initial или Auto.
Для небольших проектов и тестовых окружений часто достаточно простого размещения приложений на VDS, а когда кластер вырастает — VPA помогает экономить ресурсы и держать предсказуемую утилизацию без ручной «подгонки» requests.


